Decomposing Drafts

When thinking about drafting from a data modelling perspective your first instinct is to consider every hero as completely unique, and so a draft is just a series of decisions (~127 to start!). Your second step is to immediately cry as you realize how huge the problem space is - the number of possible 5v5 lineups is around half the number of grains of sand on earth. To make progress in this problem there needs to be some dimensionality reduction.
Dimensionality Reduction
One approach is hero vectors - the first article I saw on this was Gavagai on Federico Vaggi’s blog almost 10 years ago, and this was the first approach I followed here. I have a variety of (role, lane) data on datdota - partially hand-curated and partially calculated by a simple ML model. I took all the patch data from 7.40 (the last finished patch), all the features that the existing model used and added in several more viable features. From there I made a correlation matrix to find the highly correlated features, and a PCA on the leftover features to prune even more noisy low-information features.
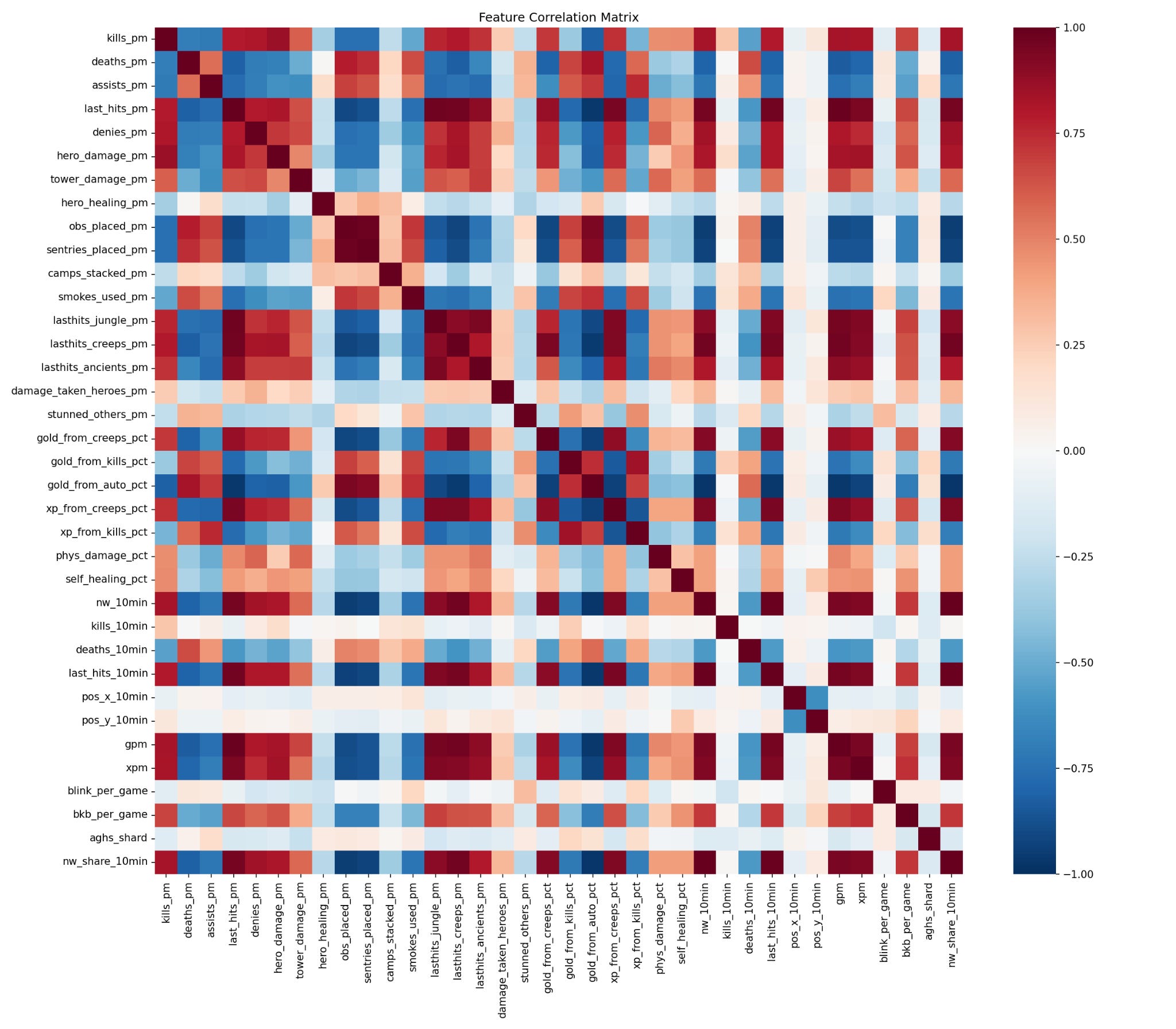
Then some normalization and after it’s all said and done we’re down from 40 features to 27 features to just 13 PCA components. From this we can form some clusters using UMAP.
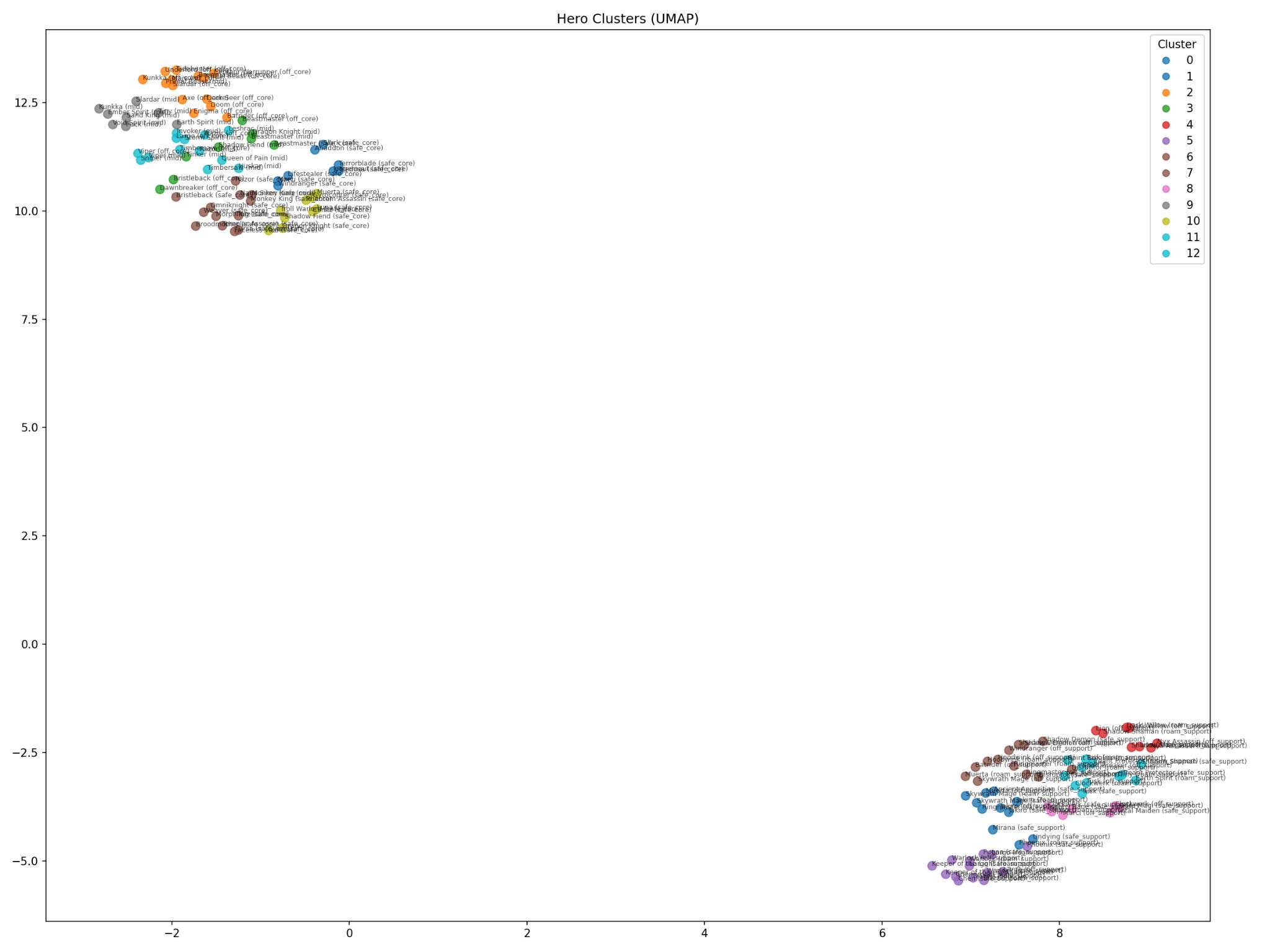
(and in a table form …)
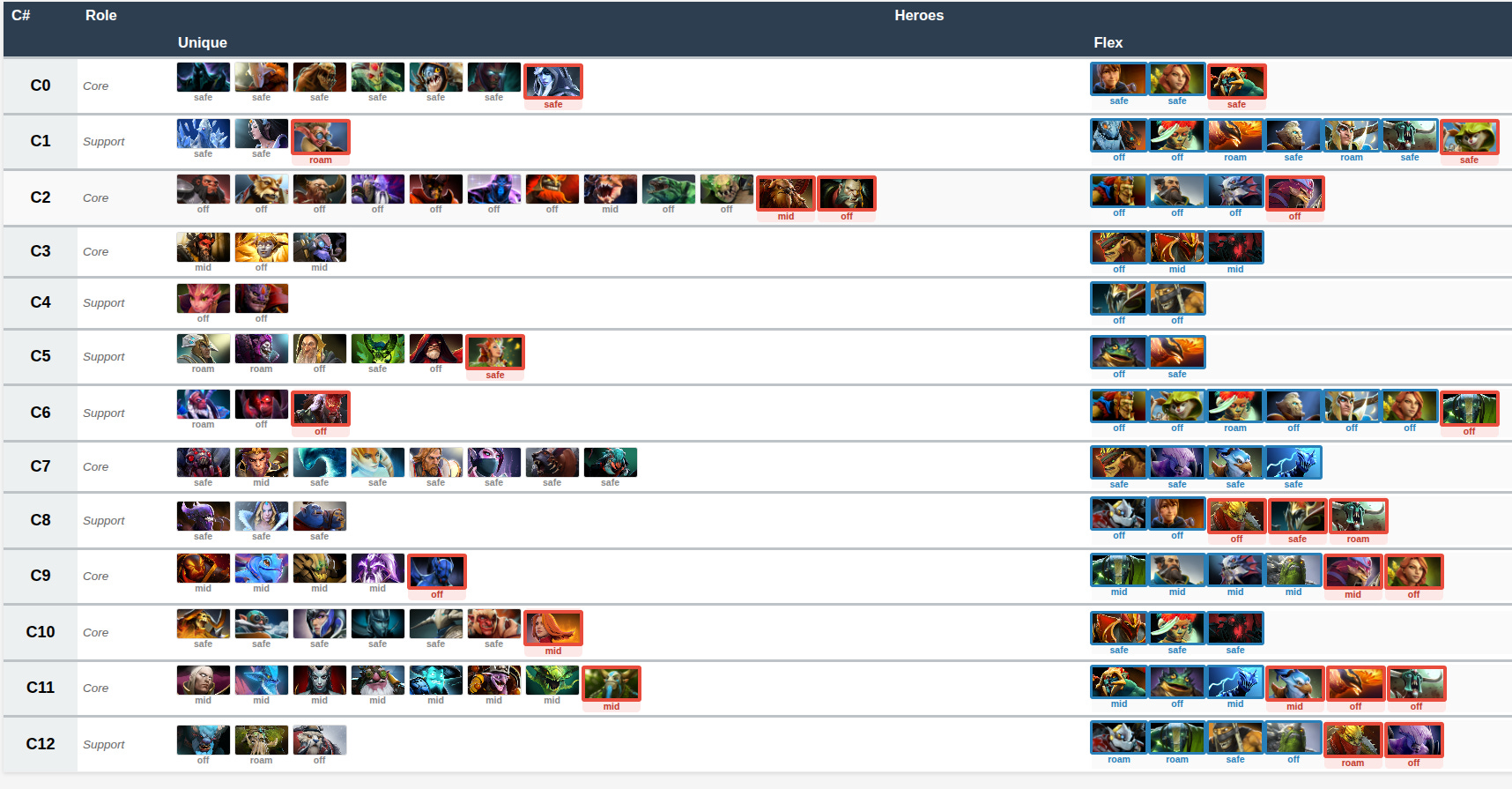
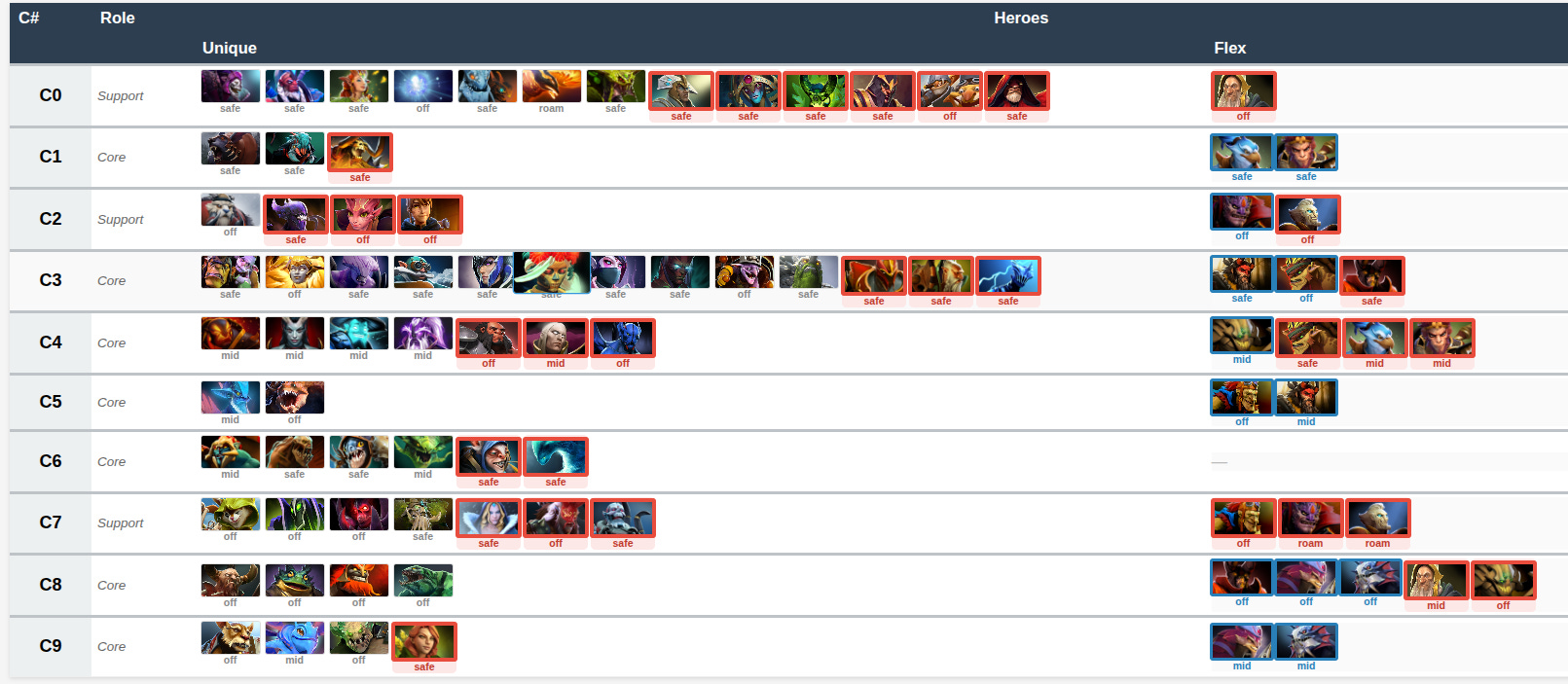
In this table view:
“unique” are heroes which only appear in one (role, lane) setup
“flex” are heroes which can have multiple (role, lane) options
.. and the heroes with a red border are a bit more uncommon (< 20 in that lane/role combo in the dataset)
Remember that clusters here are based on their underlying statistics at key points in games - so they can be viewed as approximate replacements for each other (although if it’s in different lanes you might need to do a two-way swap to get the same overall effect). Instead of 127 unique heroes we now have 13 clusters of heroes (7 core clusters + 6 support clusters).
Looking for Patterns
Now we can look at support pairs and core pairs (as in, all pairs out of the three cores) to see any patterns.
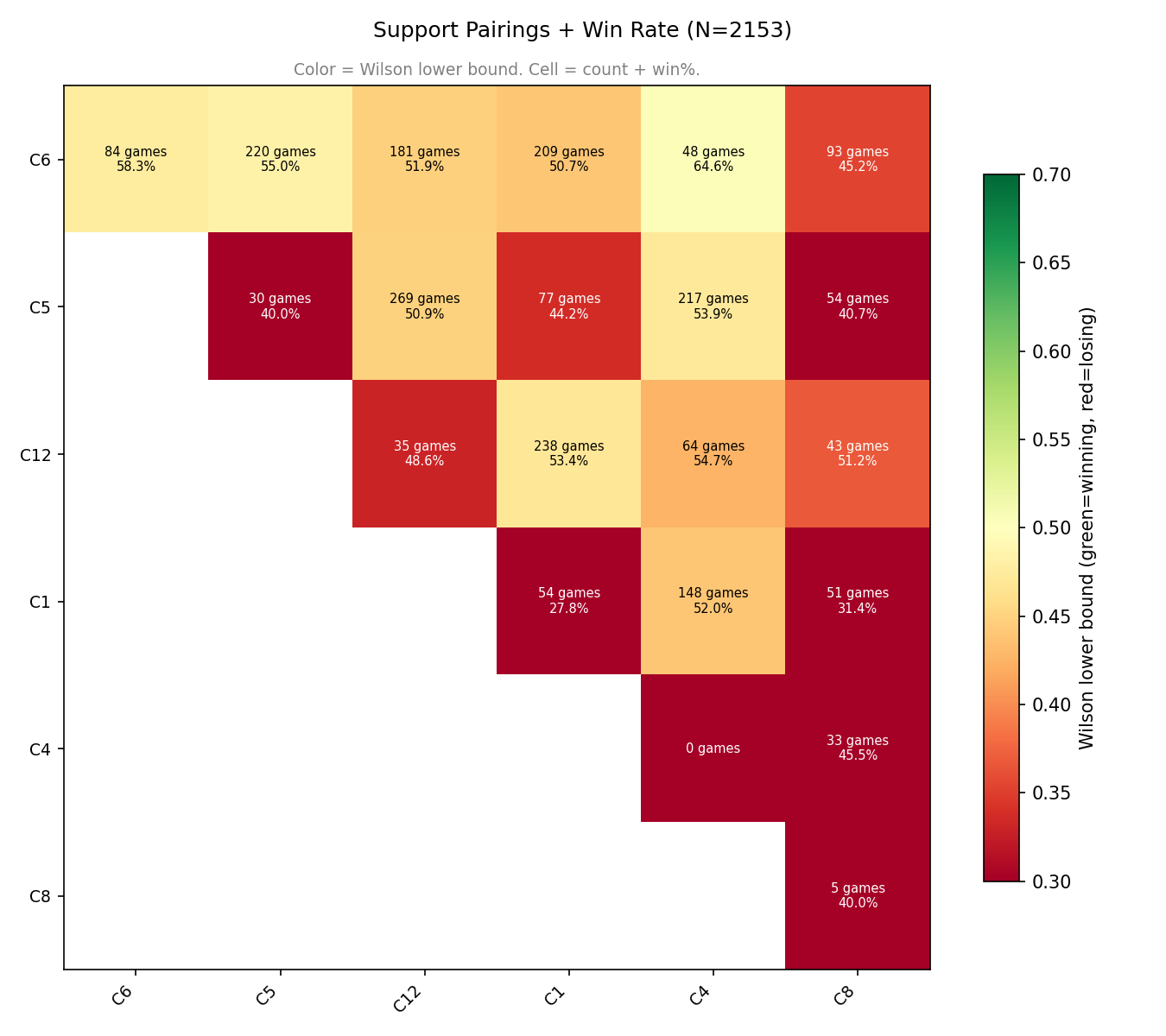
It’s worth looking at a few examples in here:
notice how support cluster C8 (Bane, Crystal Maiden, Ogre, Clockwerk-offlane, Marci-offlane, etc) has a pretty terrible winrates when combined with every other support cluster except for C12 (Spirit Breaker, Treant Protector, Tusk, Clockwerk-roam, Earth Spirit-roam, Shadow Shaman-safe, Tiny-off, etc).
C6 (Disruptor, Hoodwink, Shadow Demo, Batrider-off, Muerta-roam, Ringmaster-off, Skywrath Mage-off, Windranger-off) is exceptionally popular and stable - only C8 is a poor partner for it.
Cluster C5 (Chen, Dazzle, Keeper of the Light, Pugna, Warlock, Largo-off, Phoenix-safe) is great with C6 (above) and C4 (Dark Willow, Lion, Nyx Assassin, Shadow Shaman-off); acceptable with C12; and poor with any other combination.
C6 is the only cluster where it’s reasonable to draft 2 heroes from.
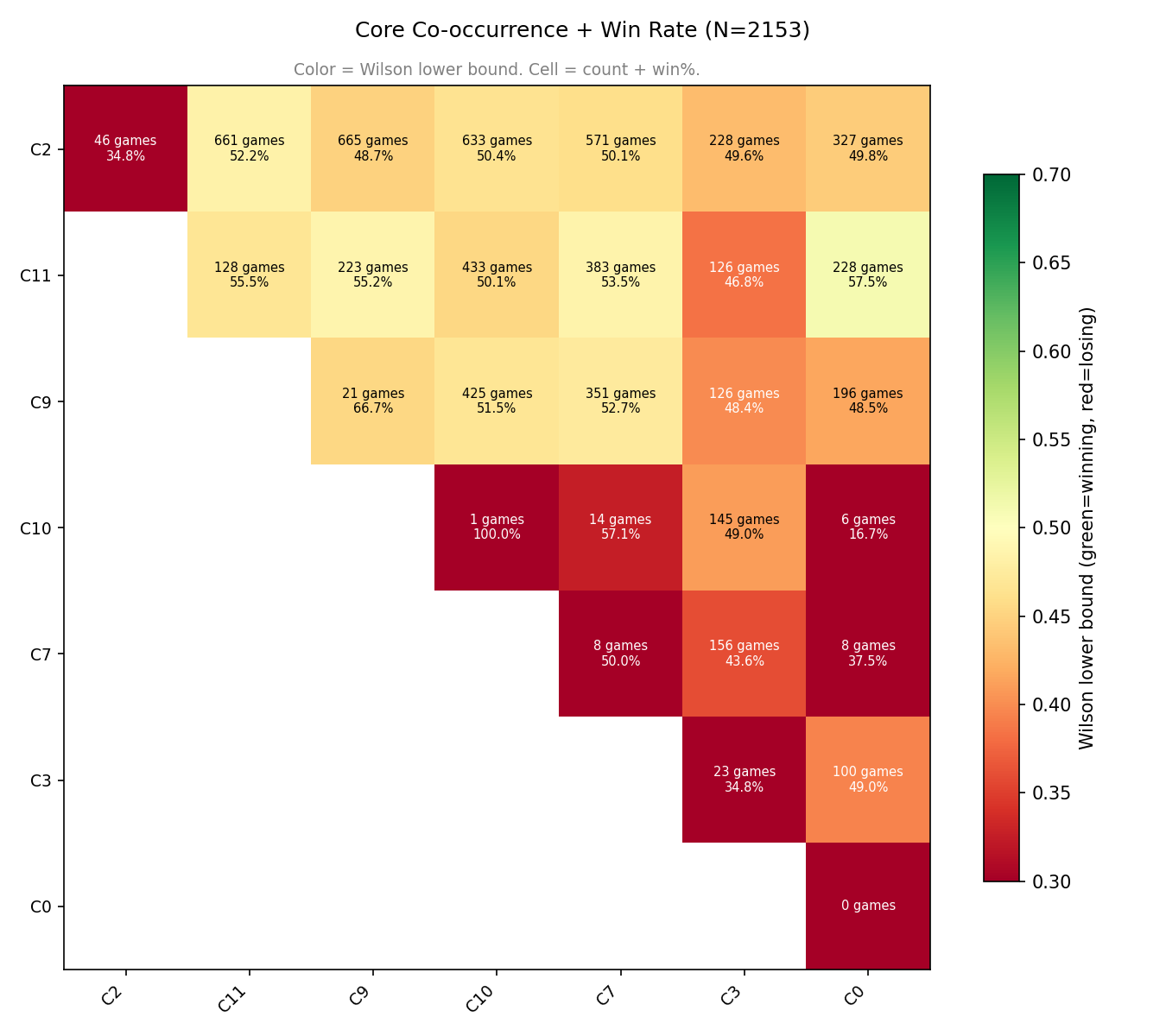
Now for the core pairs:
C0 (Abaddon, Jugg, Lifestealer, Medusa, Slark, Terrorblade, Drow, Marci-safe, Windranger-safe, Huskar-safe) are:
Decent with C2 (a lot of mostly tanky offlaners who are able to frontline and run interference) or C9 (mostly strong initiator mids with great extended teamfight skills)
Good with C11 (“standard” mids from the patch)
Terrible with everything else
C3 seems generally avoidable (doesn’t have a single pair > 50%)
C11 has favourable pairings with every other cluster (except C3).
We can also look on a team-by-team basis, for example Tundra cores (83 games), but can be a bit more forgiving on smaller samples) …
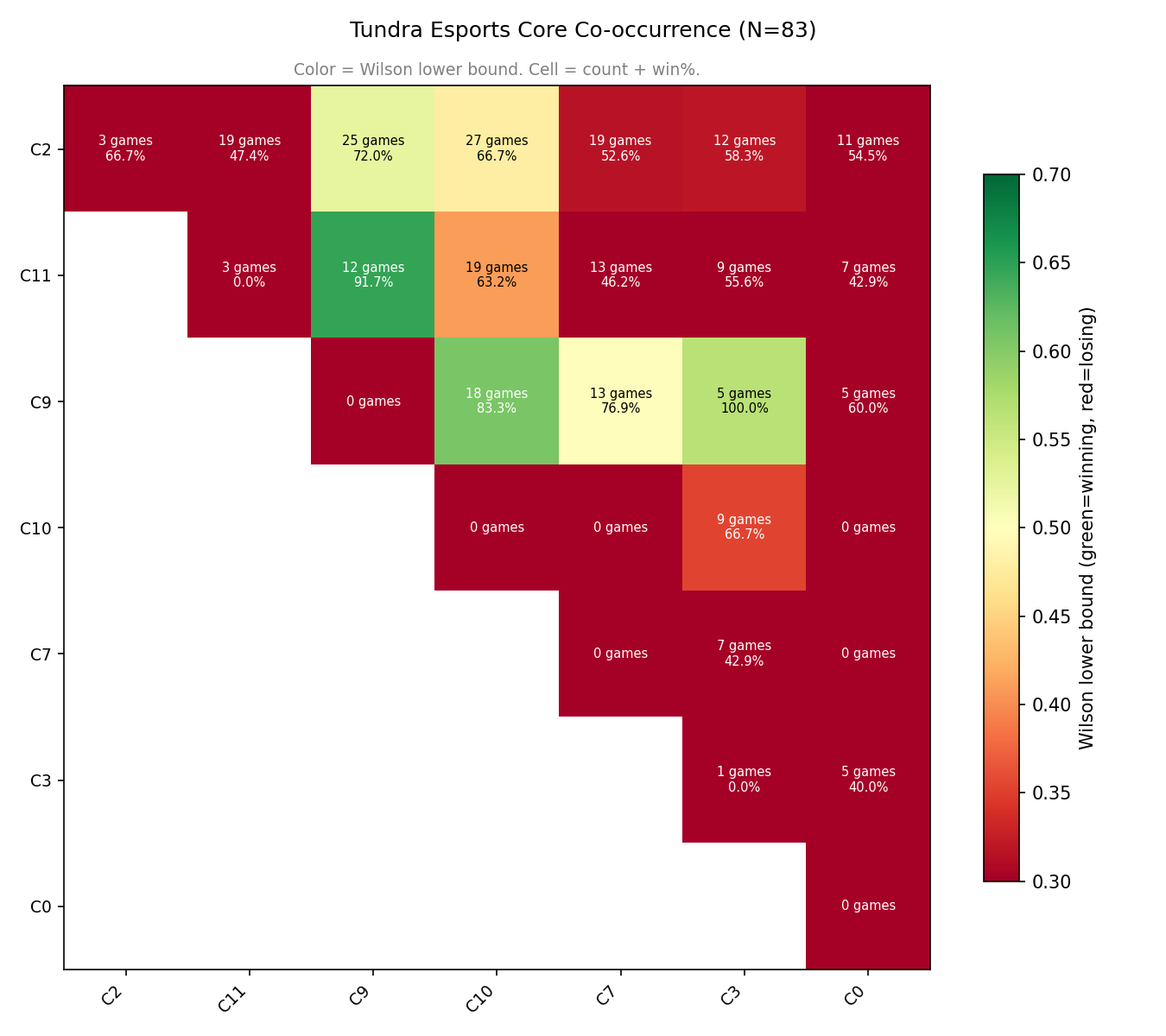
They’re a team which has had the most success with C9; or with {C2 or C11} with C10. C2 (the large group of conventional offlaners) is decent-good in all their games except C11 - some of the more conventional mids.
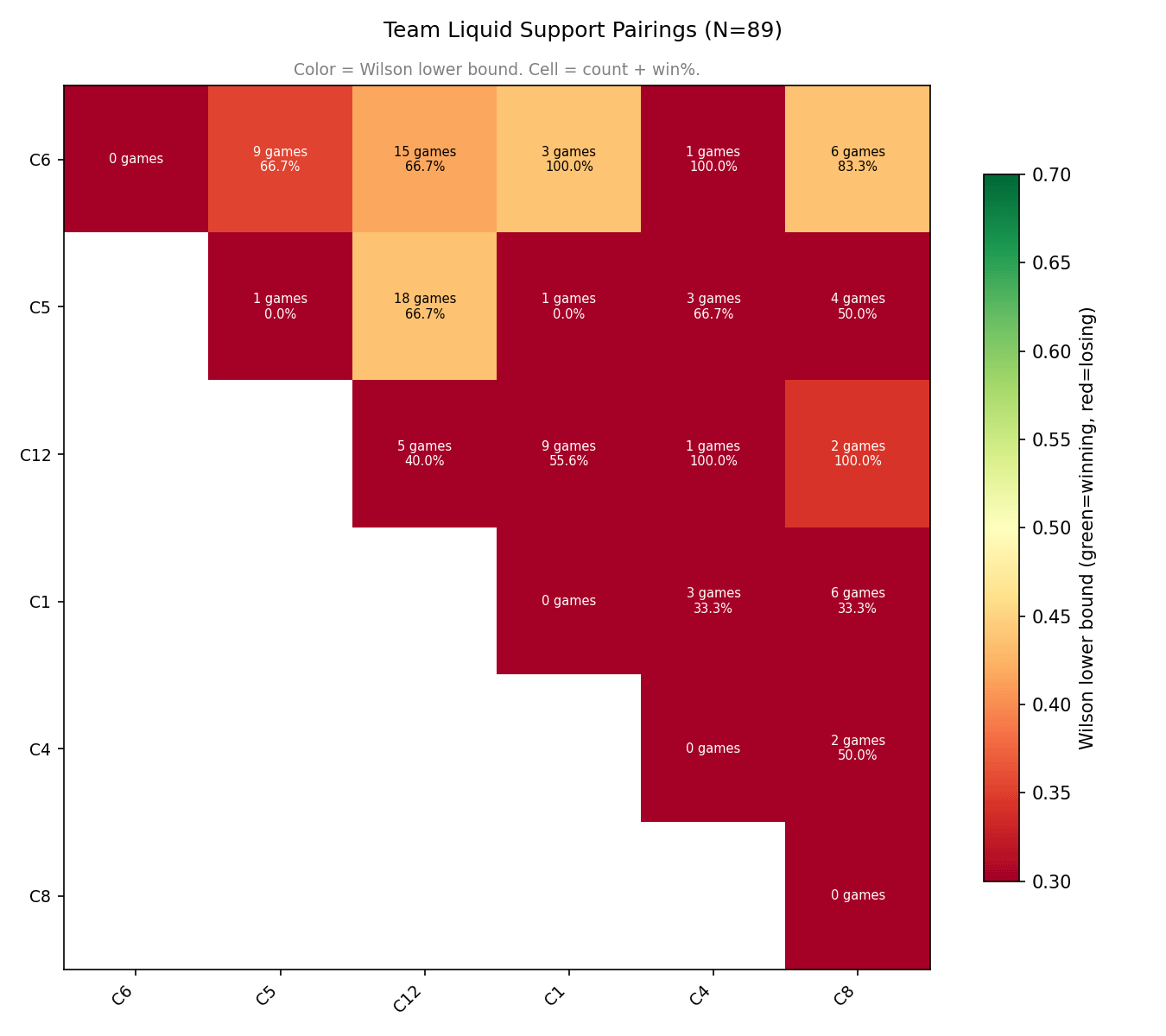
Team Liquid has a lot of support combos involving C6 (many of their most successful pairs); and C12 (paired with C5/C6/C8).
So how is this just better than just considering hero pairs? Well, firstly it provides a statistically driven method to cluster heroes together based on their key metrics: what they bring to the table, and who could replace them if they’re banned out or counter-picked.
It also can group teams together based on how they draft - teams with a very similar draft “blueprints” are likely to approach the game in a similar way. Drafters can also use it to prioritize picks - for each cluster there is a set of heroes which players on the team are practiced on, so as a draft is ongoing you can keep track which good combinations are/aren’t still available. On some patches this is really important - there might only be a few permutations which are good and with a few key bans you can force the draft to go in a way that’s favourable to your team. Finally, we can use this as a method to identify unusual or suspicious drafts.
What about 7.41?
We’re still pretty early in to the new patch but we can apply this same pipeline to the data (~770 games).
The first observation to make is that there’s only 3 support clusters - and all the well performing pairs have at least one from C7.
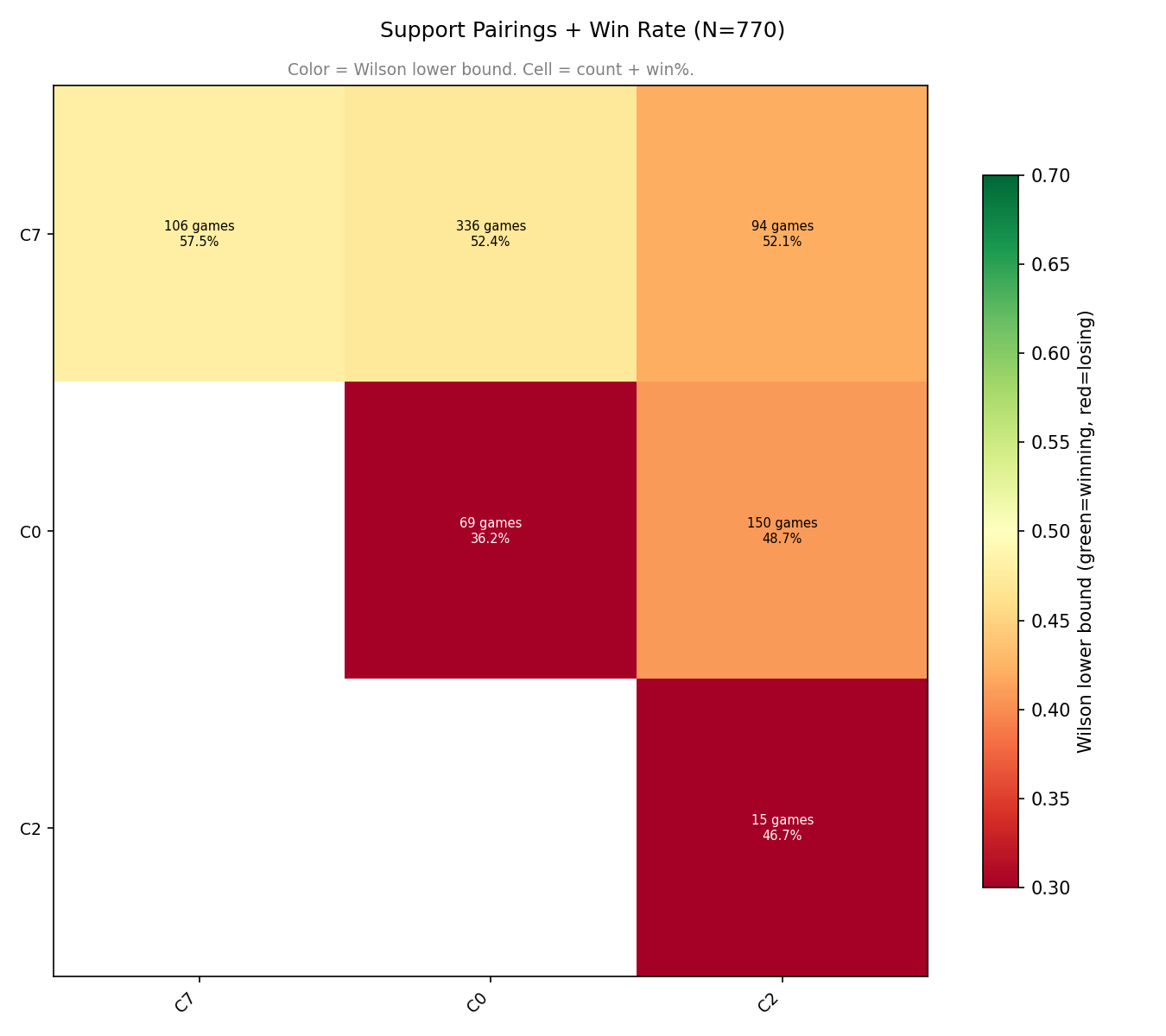
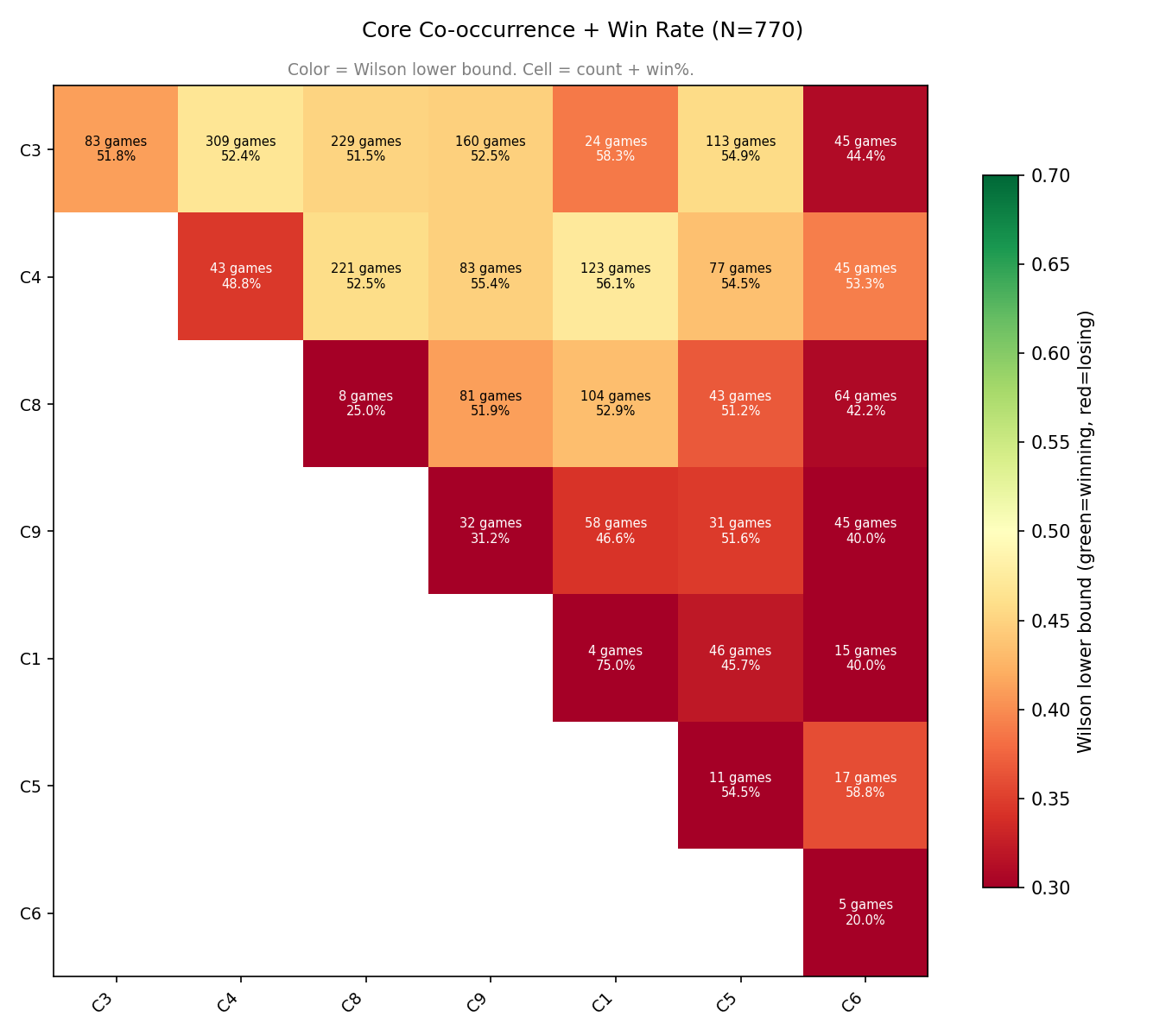
For cores:
C3 is a stable pool of greedy heroes - mostly offlane or safe lane. They work well with any other core cluster except C6 (Huskar, Lifestealear, Viper, Meepo, Morphling).
C4 is also a popular cluster in any combination except if you double-up on it. No other cluster should be doubled (poor winrate or just a tiny sample)
C8 is the only other stable option with multiple co-clusters (C9/C1)
Next Steps
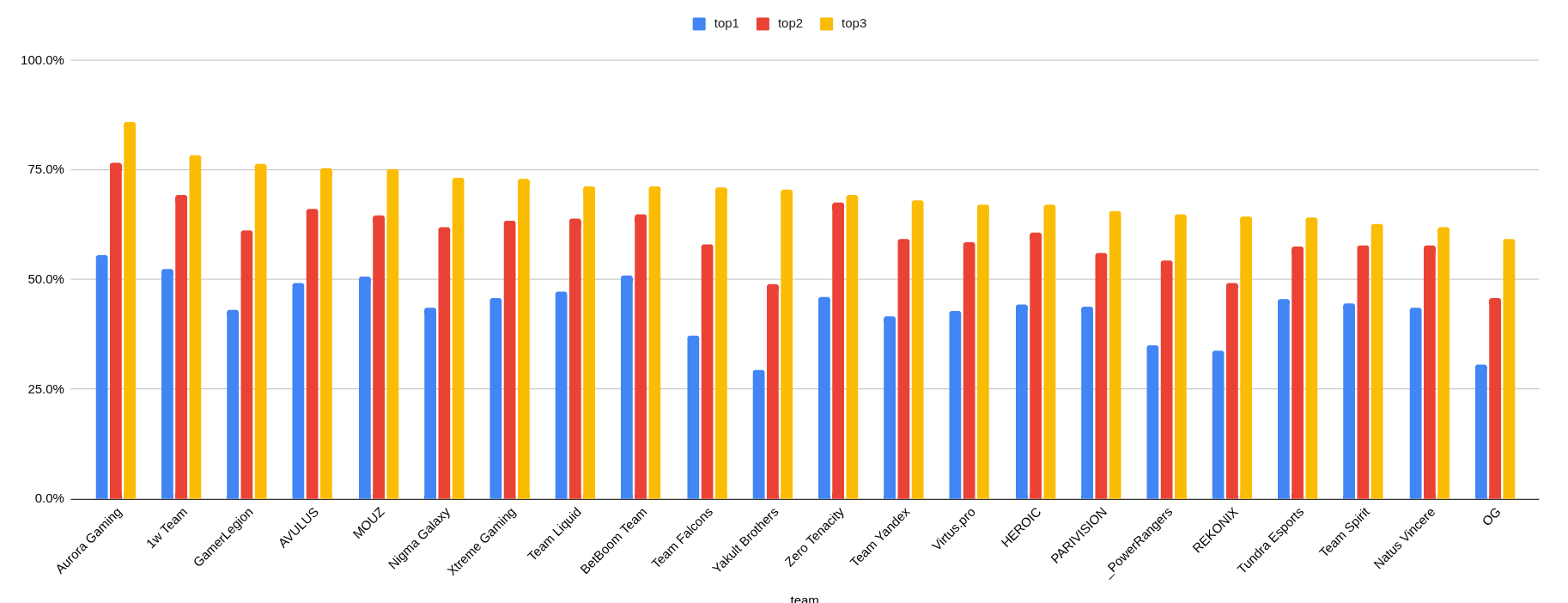
Overall I think this approach has a lot of potential but it needs some more work to visualize the findings in a more accessible manner. We can also use these team “blueprints” to create a simple 4th or 5th pick model considering only that team’s picks (ignoring bans and what the enemy has picked). As you can see in the graphic above (for 7.40), some teams like Aurora and 1win have their 5th pick predictable at 55.6% / 76.8% / 85.9% given 1 / 2 / 3 cluster guesses; whereas a team like OG is much lower (30.5% / 45.8% / 59.3%). Given more context like the hero pools, these cluster predictions could form part of a much more accurate draft prediction model.
I also think there’s also more unique statistics that can make the cluster formation more accurate - although give the number of games we deal with per patch, it might not be that helpful (but worth doing anyway!).
Until next time, Noxville