

Source 1: any% complete (for now)
Some of the games might be 10 years old, but we still care about them!

As I suggested in a prior post, I was going to spend some time working on a Source 1 parser. With a few weekends and the recent long weekend, I was able to get a v1 out a lot more complete and a lot faster than I expected. I built it mostly off of TI3 and TI5 data, for which there is reliable and good quality VODs available (being able to quickly look up something on video made development a lot easier).
Progress Report
After the first version came out, I parsed a bunch of the replays, hoping to roughly clump them into categories:
parses fine, output is good
parses fine, output is bad
does not parse
no replay available
As always, there turned out to be many more cases and subcases - but the first run-through was mostly a success. After some tinkering and bug hunting I reparsed the dataset again. Parsing the 16330 replays took approximately 64 hours (running 2 in parallel on the same machine with a AMD Ryzen 9 3900 12-core + SAMSUNG MZQLB1T9HAJR-00007 NVME; which is also a production server for datdota and windrun.io), and ingesting them into the database took another 17 hours.
Of the 18772 matches played in Source 1:
86.62% were parsed and ingested successfully
9.58% were not parsed due to a missing replay - either the replay wasn’t on the Valve CDN, or the replay cluster was deleted, or the file on the CDN wasn’t a valid bz2 file, or the bz2 file had an invalid replay in it
2.96% were not parsable because of mangled or unexpected data in the replay.
0.45% there was a replay on the CDN, and it was valid — but it was for a TOTALLY DIFFERENT AND RANDOM pub Chinese match. These were mostly on cluster 223.
0.39% are broken but possibly recoverable with a lot of effort.
86.62% is a reasonable number, but it’s still a big step down from the ~98.68% parse success rate in Source 2.
In total it was around 30 hours of coding for the first version, another 12 to 16 for all the subsequent updates, and lots of little segments of time during the parsing process to make sure things were going smoothly.
In terms of general data quality, some things are missing in Source 1, either because it doesn’t exist (some frame fields, neutral items, tormentors, etc) or because they were not implemented.
Under the Hood
There are a few different ways in which data stored in replays can be extracted:
combatlog: this is a detailed log of specific game events, including units doing damage, casting spells, gaining gold, etc. Only events which Valve decides to store in the combatlog are stored in this ledger.
game messages: these are the sort of rich text messages which appear like “The Radiant have killed Dire”, “Bob is on a killing spree”, etc. Once again, only events which Valve decides to make as messages are made into them. These are helpful as deciders for potentially complex events like "Bob has got an ultra-kill!”, but also can result in oddities like when Meepo dying gives the killer a rampage.
entity changes: perhaps the most raw types of state changes are the creation, updates, and deletions of entities. These represent objects within the game (heroes, buildings, cosmetics, items) as well their properties (visibility, location, yaw, animation state, etc). They’re also used to store abstract information such as the draft, rules about the game state, etc.
Combatlog entries are the most desirable because they are generally the most accurate and long-lasting in definition. Game messages can change over time and are sometimes not backwards compatible.
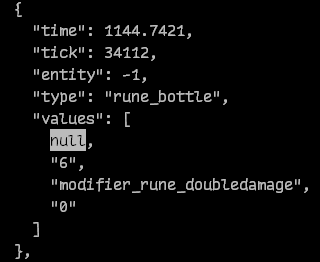
Entity-related parsing is the most frustrating because logic frequently change, there are often loads of edge-cases, and the parsing process slows down greatly because you need to check each updated entity if it’s of a type you’d like to investigate. It can also be a lot of work to calculate even a simple event (for example, which hero could possibly be close enough to a rune to deny it? oh yeah just use the distance formula to see who is close! oh what about illusions, controlled creeps, and summons?)

Teamfights are one thing I just refuse to port - the code that manages it in S2 is very complex, and there’s no reliable tests. Also, the data that comes out is difficult to package in a useful way for datdota users (although I’ve looked at the data a lot for various ideas).
Frames have a few fields that are unreliable or inaccessible (I won’t persist the unreliable ones) but are mostly good.
One day I will probably return to fix up the 6.78 to 6.80 Buybacks and 6.80 to 6.81 Rune events which are broken; and possibly all the Item Purchase events.
Draft data from 6.74 to 6.76 is something I’ll almost definitely work on - the data is in the replay but just wasn’t part of the WebAPI until later. I’ll probably make a throw-away basic parser to collect just this data in the right format.
Multikills are not interesting enough for me to look at directly, but I do have the raw kill events so maybe I’ll just synthesize them. For First Bloods I have fixed all of the issues I found, but I expect there could be more — there’s a lot of edge cases after all.

All in all it was a quite fun adventure. The database grew by 30GB, and now stores a lot more data and history of the Dota 2 pro scene. If you spot any errors (which I’m sure exist), feel free to reach out!
- Noxville